Getting to 5 Million: HathiTrust’s Collection of Open Books
April 10, 2015
Just before the end of March we reached a significant milestone when we added the 5 millionth volume that is open for reading and downloading. Like any research library collection, HathiTrust is nothing if not eclectic, as evidenced by our 5 millionth volume, contributed by Ohio State University: A treatise on the disorders and deformities of the teeth and gums, explaining the most rational methods of treating their diseases by Thomas Berdmore (London, 1770). Berdmore was King George III’s dentist. According to his VIAF record he died at the age of 45 and his work was also published in Dutch. (Alert the medical historian in your family!)
Earlier this week, Rick Anderson offered in the Scholarly Kitchen a nice commentary on the significance of this event for the public at-large and for the library community. Rick sketches the broad outline of how we got here today, through partnerships with Google and among research libraries. I want to add that the HathiTrust collection is the product of hundreds, if not thousands, of people at our 105 member institutions, at Google, at Internet Archive, and many other content producers and distributors. This includes executives and front-line staff, librarians and publishers, technologists and end users. It’s an honor to be involved with it today.
In this post, I’d like to go into some detail to shed more light on the characteristics of these materials, our work to open them, and how we are endeavoring to make them as useful as possible. Numbers geeks, get ready.
Public Domain and Open
I’m referring to 5 million open works not public domain works. That’s because nearly 20,000 works in this this group have been licensed by the rights holder to be opened for public display. (That’s a very small percentage, but is still a substantial number of affirmative choices to support open access). We’ve tended to use the “public domain” as shorthand for the entire set of works, but in this post I’ll split hairs to better explain our processes and policy.
Some of our collection is public domain only in the United States and thus can’t be accessed outside of the US (there is also a portion that are in the public domain only outside the US). Here’s a snapshot as of April 1. (The total number of volumes held in HathiTrust on that date was 13,305,071.)
| Status | Count | Percentage of Open Works | Percentage of Entire Collection |
| Public Domain – Worldwide |
3,080,031 |
61.54% |
23.15% |
| Public Domain – US |
1,901,044 |
37.98% |
14.29% |
| Public Domain – Only outside US |
4,451 |
0.09% |
0.03% |
| Total Public Domain |
4,981,075 |
99.52% |
37.44% |
| Creative Commons and Open Access Licensed |
19,425 |
0.39% |
0.15% |
| Total Open Volumes |
5,004,951 |
100% |
37.62% |
Furthermore, these 5 million volumes correspond to 2,365,771 unique titles. This is because some of these titles are multi-volume works. At the end of this post I’ve appended a few links and graphics to provide you with more detail about the nature of the collection. I don’t have space to discuss each one here, but take a look and comment if you have questions.
Let’s look at how we determine the rights status of books in HathiTrust.
How did we get 5 million open volumes?
There are several processes that we use to determine if we can open a book for public view.
Automated bibliographic metadata review
Whenever an item is added to the collection, an initial automated rights determination is made using information in the item’s bibliographic metadata, such as publication date and place of publication (details of the process are available on our website). For United States works, anything published before 1923 is identified as being in the public domain worldwide. US federal government documents, no matter when they were published, are identified the same way. There are more than 612,484 federal documents available in the collection today.
Because copyright term in other countries is often determined by the death date of the author, and because the term varies country by country, it’s harder to verify copyright status of works published outside of the US. We’re cautious here and will only open works published outside of the US 140 years ago. In other words, all works published before 1875 are now marked as public domain worldwide. We treat works that were published outside the United States less than 140 years ago but before 1923 as public domain only when viewed from within the United States. There are a small number of works that are in the public domain only outside the United States. These are manually determined to be so due to provisions of the General Agreement on Tariffs and Trade (GATT).
More than a third of the total collection is thus made available, but a lot is left marked as in-copyright or of undetermined status. Because we know that much of this may be in the public domain, we also have a manual review program for some significant parts of our collection.
Manual Copyright Review: the Copyright Review Management System
Since 2008, the University of Michigan has had National Leadership Grants from IMLS to fund the development and operation of the Copyright Review Management System. This ambitious project draws on the expertise of copyright specialists at Michigan and research skills contributed by staff in dozens of partner libraries. CRMS incorporates a double-blind review process, in which two persons at different institutions are randomly assigned a work in a designated review queue to investigate. Two reviewers must confirm that an item is no longer protected by copyright for us to open the work. Split decisions are reviewed by a third, expert reviewer. If the evidence is incomplete and we can’t determine, we err on the side of caution and keep the work closed for viewing. (The full text of works that are not available for viewing is still available to be searched.)
The first phase of the project, CRMS-US focused on works published in the US from 1923 to 1963, during the period when copyright status had to be renewed or certain formalities had to be followed to receive protection. The second phase, CRMS-World, has focused primarily on works published between 1876 and 1944 in the United Kingdom, Canada, and Australia, and uses primarily author death date and place of publication as factors to determine copyright status. The CRMS team also worked with the Berlin School of Library and Information Science at Humboldt University on a pilot project involving German language materials.
Over the past six years the CRMS project staff have reviewed 511,520 items and have been able to open 270,979, or 52.96%. In this final year of IMLS funding the team is developing a toolkit for future work on copyright determinations, and we’re examining what other parts of the HathiTrust collection might be well suited for this distributed, manual review process. We’d like to hear from any of you who have ideas about how this project could be expanded in the future.
Permission of the rights holder
As noted above, a small portion of these 5 million books are, strictly speaking, not public domain, but are licensed for public access, either through a Creative Commons license or a more general license for open access. This includes items licensed by individual authors (e.g., http://hdl.handle.net/2027/mdp.39015038573807), a publisher, such as the Brooklyn Museum, or some other creator or agent stewarding the rights of various works.
Giving permission to open your work under a CC or other license is straightforward, and we have instructions online (Link http://www.hathitrust.org/permissions_agreement). We’re more than happy to discuss this process with anyone interested, and can help with gathering the information needed for a large number of items.
Using Open Works
It’s our goal to ensure that the works that are open access or in the public domain are as widely accessible and usable as we can make them. To aid discovery we’ve been serving as a content hub for the Digital Public Library of America since 2013, and any of the open works are findable through their outstanding search interface. All of these 5 million items can be read online in the United States and users can download pages of the works regardless of whether their library is a member of HathiTrust or not; just over 3 million of them are available in this way anywhere in the world. More than 600,000 items carry no license restrictions (read more about restrictions) and can be downloaded in their entirety in the US; 380,000 are available for full download worldwide. Users at member institutions may download full copies of a broader range of works when they authenticate via their institution.
Third-party agreements and licenses may govern what you can do with some of the works you access. For example, the full range of Creative Commons licenses, from CC-BY to CC-BY-ND-NC are in use in the collection, and works digitized by Google can be accessed via HathiTrust, but may not be re-distributed or re-hosted. You can get more details about appropriate use of works by looking at the rights designation indicated for each. We explain the meaning of our rights designations here: http://www.hathitrust.org/access_use
Public domain, open access, and CC-licensed works are available for computational uses via the HathiTrust Research Center (HTRC). The HTRC, hosted by Indiana University and the University of Illinois at Urbana-Champaign, has developed infrastructure, services, and staffing to help researchers perform complex research using various data mining techniques. The HTRC has also created a dataset of extracted features derived from open volumes at the page level. It includes line counts, sentence counts, and counts of part-of-speech, e.g., nouns, verbs, etc. Through a recent grant from the National Endowment of the Humanities we’re also making an n-gram viewer using the Bookwork software, which allows anyone to track the appearance of words over time in the “public domain” corpus: http://bit.ly/1CndJle.
Beyond 5 Million
We’ll continue to increase the number of open items in HathiTrust, through natural growth and specific programs. As part of our Government Documents Initiative we are continuing to identify US federal publications in our collection that were not correctly cataloged, and many of our contributing members are still scanning these materials in large numbers. By the end of the year the number of federal documents should increase by tens of thousands at least. We’ve also been quietly working with several publishers and other organizations to collect and open more materials in the collection. And we are analyzing the collection to identify potential pools of materials that can be manually reviewed using the CRMS processes.
HathiTrust–that is, the entire collective of members–is proud to provide access to these 5 million volumes. But there’s still a lot of material to collect. In Rick’s Scholarly Kitchen post, he argues that libraries who “consider themselves to be on the front lines of providing open access to scholarly information” should be actively considering how to digitize and make accessible collections that can be made available without restriction. I agree with him, but please don’t forget that in-copyright works in the HathiTrust collection are also very valuable and can be used lawfully in specific ways. Everything is searchable–all 13 million volumes, regardless of copyright status—and we are planning to offer non-consumptive services on the entire collection through the HTRC (read more about the HTRC Data Capsule). In-copyright works can be made available to users at member institutions who have a print disability, opening up many more millions of volumes for a significantly underserved population of library users. Finally, in the United States we provide access for lost or damaged and out-of-print items under Section 108 of the Copyright Act.
These are all good reasons, supported by law, to continue to digitize in-copyright works, and this shouldn’t be forgotten. It’s our mission to preserve the record of human knowledge for future access. There will be a day–far in the future perhaps, but the day will come–when all of today’s HathiTrust collection will be readable by anyone. We’re preparing for that day now.
Appendix: Additional Data and Visualizations
Our Statistics and Visualizations page provides reports about the distribution of languages, publication dates, and LC-classifications for the public domain (open) collection and the collection as a whole. These are updated each day, but here are some snapshots as of the April 8, 2015, the day I am completing edits to this post.
Language Distribution of Open Works in HathiTrust, April 2015
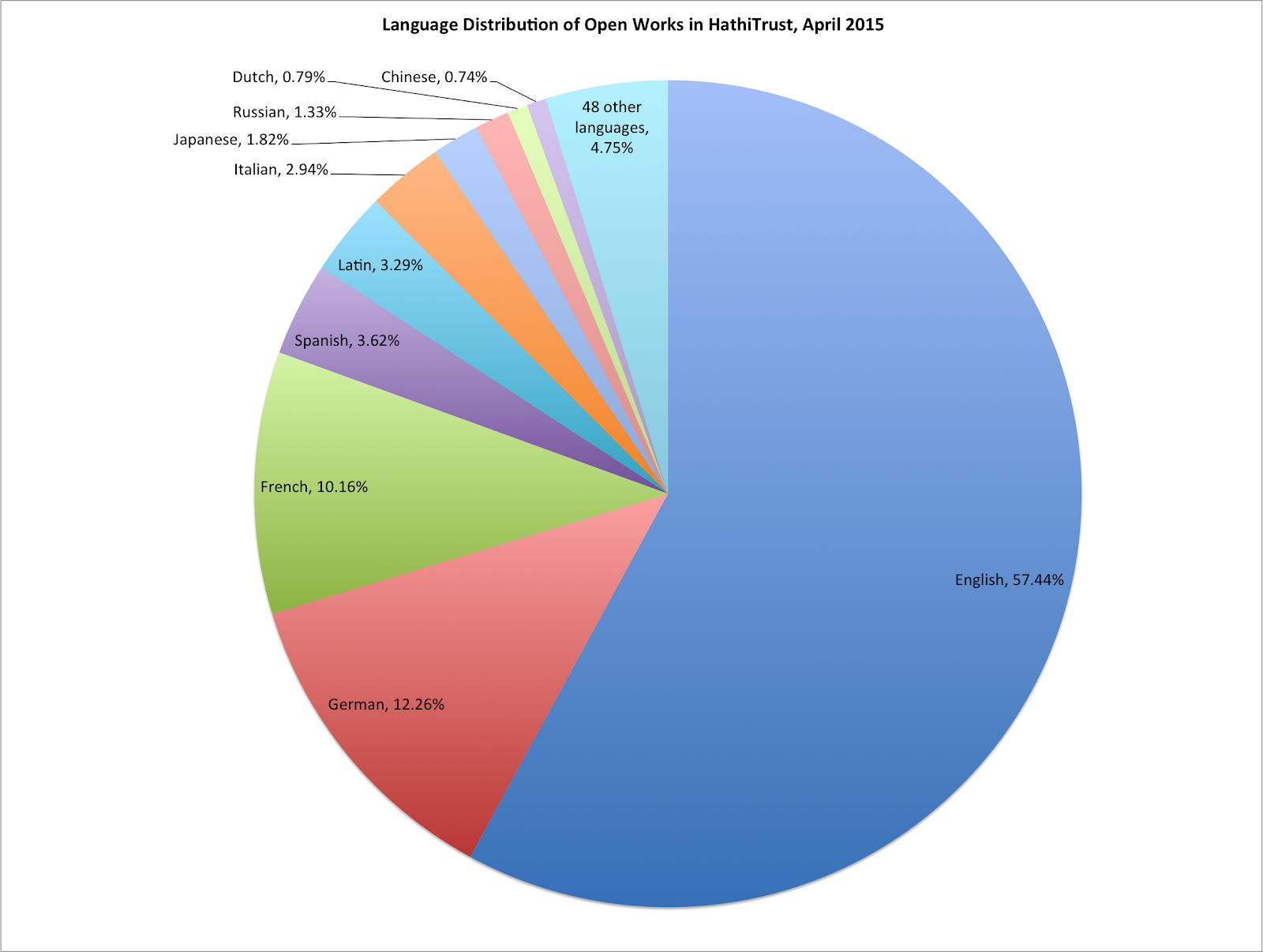
English is closer to 50% of the entire collection, but because the CRMS project has focused primarily on English language materials it represents a larger part of the public domain collection.
Date of Publication Distribution of Open Works in HathiTrust, April 2015
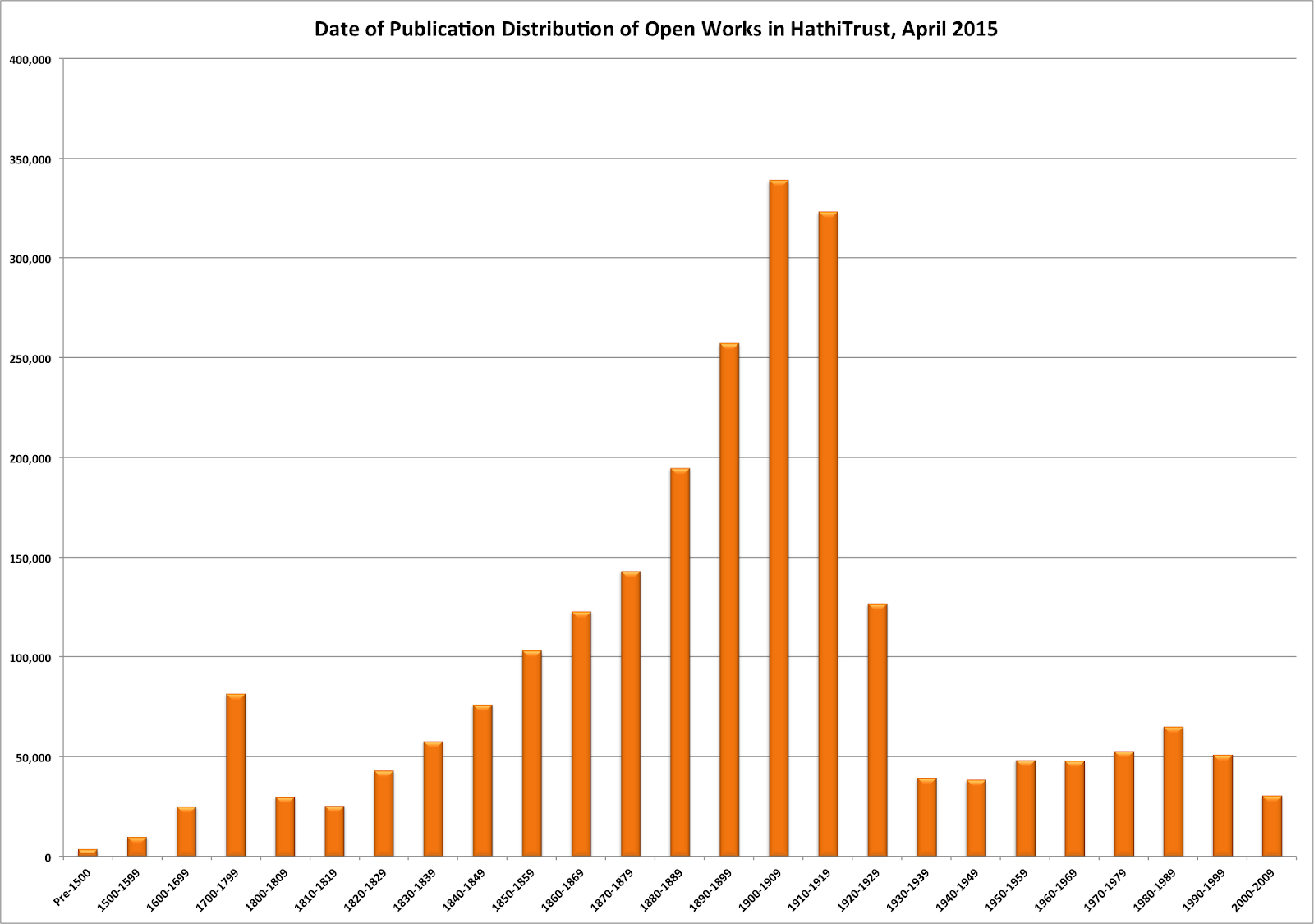
Not surprisingly, most of the open works are were published in the late 19th and early 20th centuries. The slight uptick from 1970s-1990s is mostly likely due to the increasing numbers of US federal documents published in that period. Because the majority of our collection was digitized from library circulating collections, we have very little material dating before 1800.
Type of Works
In addition to these reports, we track other characteristics of the collection, including the type work. The table below provides a recent snapshot of the collection by the type of work.
| Type of Open Work | Number of Volumes | Number of Unique Titles |
| Single-volume monograph |
2,416,746 |
1,922,399 |
| Multi-volume monograph |
1,083,469 |
330,699 |
| Serials |
1,519,766 |
11,2673 |
| Total |
5,019,981 |
2,365,771 |
Overlap Analysis
Finally, we can track the prevalence of public domain works in the collections of HathiTrust Members. We periodically create graphics we call call “H-plots.” To get these we run an overlap analysis for each member library’s collection holdings against the rest of the membership (see HathiTrust Print Holdings for details about the information we use in matching). This gives us a sense of the “uniqueness” of a member’s collection. In the example below, which I picked at random, we see how widely distributed are the items in the Library of Congress (LC) collection.
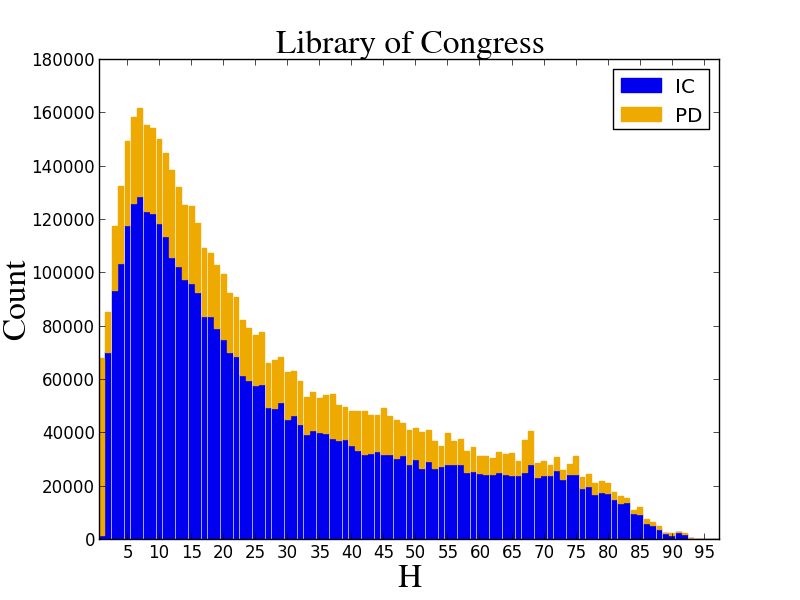
Here the X-axis is the number of times a book is found on the shelves in a HathiTrust member library; the Y-axis is the number of items in the collection that are duplicated. So, for example, there are about 160,000 items in the Library of Congress that can be found in five other member libraries, and of those about 125,000 are in-copyright and the remainder are open. This does not tell us about what has been digitized from the Library of Congress, it only reports on their physical collection holdings relative to the rest of the HathiTrust members. (In fact, every digitized item that the Library of Congress has added to HathiTrust is out-of-copyright.)
These H-plots are useful to get a sense of the general “rarity” of a library’s collection, but they may not always show a complete picture. For instance, there are items from institutions’ collections that are not represented (only items whose records include OCLC numbers are included – see the Print Holdings link above) and we may not be able to definitely match holdings across institutions (these will often show up as unique items held by an institution). Still, the H-Plots provide a view of what is known about library collections, which we expect to increase over time as we continue our work. The most recent collection of graphs is available at http://bit.ly/1Ofrjyw.