Requesting and Using Research Datasets
HathiTrust makes the text data of public domain works in its collection (listed as “full-view”) available to researchers to directly download in bulk for non-commercial research purposes. If you wish to access a dataset, complete the approval process described in more detail below.
These datasets are meant for researchers seeking large numbers of public domain texts they wish to analyze locally. The HathiTrust Research Center also offers tools and services outside of your local computing environment for text and data mining items in the HathiTrust corpus. Access to HTRC tools is separate from the research dataset approval process.
Learn more about the kinds of research that dataset recipients have published.
Available Research Datasets
The available research datasets are divided between:
- Public domain volumes not digitized by Google: available for non-commercial research by request
- Public domain volumes digitized by Google: available for non-commercial research by request for those whose institution has signed a distribution agreement with Google
Regardless of who digitized the data, HathiTrust distinguishes between works that are public domain only in the US, and thus available only to researchers in the United States, and works that are public domain worldwide and available outside of the United States. Access to data in a dataset follows HathiTrust’s policy for access to public domain materials. The worldwide public domain datasets are subsets of the volumes available to researchers in the United States.
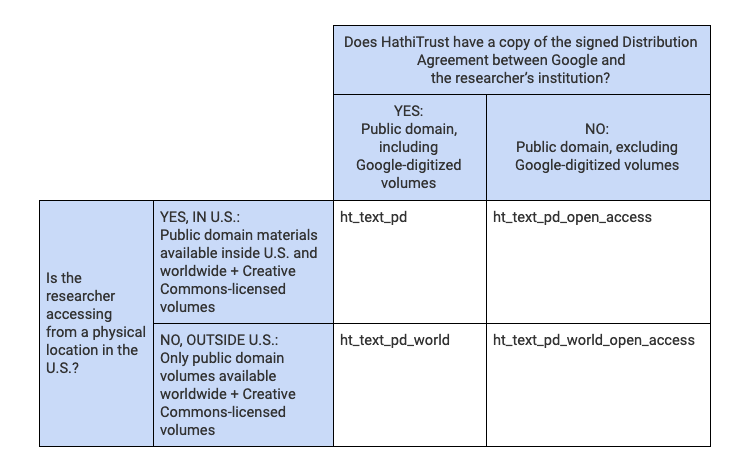
Public domain text, excluding Google-digitized volumes
Dataset for researchers in the U.S.: ht_text_pd_open_access
Dataset for researchers outside the U.S.: ht_text_pd_world_open_access
- 814,045 public domain and Creative Commons-licensed volumes as of February 2019 for researchers in the United States (610,575 for researchers outside the United States). Total dataset is at least 480GB for researchers in the United States (351GB for researchers outside the United States).
- Due to variation in the length of copyright protection in different nations, the version of this dataset available to researchers outside the United States represents only the public domain volumes that are public domain anywhere in the world, a subset of HathiTrust’s overall public domain corpus. Learn more about HathiTrust’s copyright determination policies.
All public domain text, including Google-digitized volumes
Researchers in the U.S.: ht_text_pd
Researchers outside the U.S.: ht_text_pd_world
- 6,649,535 public domain and Creative Commons-licensed volumes as of February 2019 for researchers in the United States (4,316,648 for researchers outside the United States). Total dataset is at least 5.4TB for researchers in the United States (3.4TB for researchers outside the United States).
- Due to variation in the length of copyright protection in different nations, the dataset of public domain volumes, including those digitized by Google, available to researchers outside the United States represents the public domain volumes that are available anywhere in the world, a subset of HathiTrust’s overall public domain corpus. Learn more about HathiTrust’s copyright determination policies.
- Includes volumes digitized by Google and those digitized by other parties.
- Represents a wide variety of languages, subjects, and dates.
- Volumes digitized by Google are available through a Distribution Agreement with Google that must be signed by an institutional sponsor in order for researchers at an institution to be able to access them. An institutional sponsor is someone with appropriate contractual signing authority at a researcher’s institution. The Google Distribution Agreement needs only to be signed once per institution, and once it has been received, it applies to all subsequent dataset requests from researchers at an institution. Researchers are responsible for understanding and abiding by the terms of the Google Distribution Agreement. In general the limits on the use of Google-digitized materials are as follows:
- Can be used only for scholarly research purposes
- May not be used commercially
- May not be re-hosted or used to support search services
- May not be shared with third parties
Accessing a subset of volumes from a dataset
If you do not need the entire sets of the volumes described above, you must limit your sync only the volumes you are interested in within one of the larger sets.
To do so, you will need a list of the HathiTrust volume identifiers of desired volumes. Volume IDs are present in the persistent identifiers for HathiTrust volumes (e.g., for the volume at http://hdl.handle.net/2027/mdp.39015021715670, the volume ID is mdp.39015021715670).
A list of volume IDs can be generated in one of the following ways:
- Using HathiTrust’s tab-delimited metadata files, called “Hathifiles”. These files are an inventory of repository holdings, containing a variety of identifiers for volumes (ISBN, LCCN, OCLC, etc.), copyright information, and limited bibliographic metadata for each volume in HathiTrust. Users wishing to select batches of materials that cannot be defined by search queries may find these files useful in selecting volumes. A description of the files is available at Hathifiles Description.
- Via the HathiTrust Bibliographic API. Can be used to find HathiTrust volume IDs for volumes with a known alternate identifier, such as ISBN or OCLC number.
- Building a collection in HathiTrust Collection Builder. Define a query or set of queries (see the search options on the HathiTrust home page) and add volumes to your collection. You can download the volume IDs for a collection.
- HTRC’s Beta Workset Builder 2.0. A beta tool and interface built over the HTRC Extracted Features Dataset to enable both volume-level metadata search and volume- and page-level unigram (single word) text search in order to build worksets for use with HTRC tools and services.
- Once you have a list of volume IDs, it can be used to generate volume paths for the rsync, as detailed in the rsync instructions described below.
For guidance and support crafting a list of volume IDs, please email support@hathitrust.org.
Data that is not available
- Data that is neither in the public domain nor licensed for access via Creative Commons licensing. Text data for all HathiTrust volumes, including those that are not in the public domain, can be analyzed using non-consumptive research methods using the tools and derived datasets from the HathiTrust Research Center under certain access conditions.
- Volumes that are restricted due to privacy concerns, such as those containing personally identifiable information (e.g., Social Security numbers paired with individual names).
- Page images. (Only provided in limited cases, and by special approval from HathiTrust.)
Requesting and Retrieving a Dataset
Datasets are available from HathiTrust only by request. If your request is approved, then you will be given access to an rsync endpoint from which you can transfer and synchronize the files. Rsync is a protocol for transferring files. See “Retrieving Datasets via rsync” for specific instructions on downloading datasets.
If you want to ask questions prior to submitting the research proposal described in step 3 below, please send an email to support@hathitrust.org to start a conversation.
The request process
- Determine which dataset you would like to request access to. Even if you want to sync a subset of volumes, you will be granted access to the endpoint for the entire dataset. Your options are:
- Public domain, excluding Google-digitized volumes: all available volumes you can access based on your location, but does not include Google-digitized volumes. Datasets are either ht_text_pd_open_access (for US-based researchers) or ht_text_pd_world_open_access (for researchers outside the US).
- All public domain, including Google-digitized volumes: all available volumes you can access based on your location, including Google-digitized volumes. Datasets are either ht_text_pd (for US-based researchers) or ht_text_pd_world (for researchers outside the US).
- For those requesting Google-digitized volumes, check whether your institution has signed the Distribution Agreement with Google.
- If not, determine who the authorized sponsor is at your institution. Because of liability and indemnification terms in the agreement, review from legal counsel could be needed. Interested researchers should begin this process as soon as possible. Email your signed Google Agreement to support@hathitrust.org to begin the process.
- If so, review the Distribution Agreement with Google to understand what your responsibilities are.
- Send a brief proposal in an email message to support@hathitrust.org that specifies:
- The name, institutional affiliation, and country of residence of all researchers who will contribute to the research project
- The dataset to which you would like to have rsync access
- Public domain, excluding Google-digitized volumes (ht_text_pd_open_access or ht_text_pd_world_open_access)
- All public domain, including Google-digitized volumes (ht_text_pd or ht_text_pd_world)
- Note: If you would like to sync only a subset of data relevant to your work but are unsure which of the datasets contains the items you desire, provide either a characterization of the desired texts (dates, languages, subjects, etc.) or details about the specific volumes requested (either in the form of a link to a public HathiTrust Collection or a list of HathiTrust volume IDs). Someone will help you determine which dataset is both best for your needs and is available to you based on the access limitations described elsewhere on this page.
- What research is to be done
- What the result outputs will be
- How the research outputs will be used
- Whether or not you give permission for HathiTrust to share the details of your proposal
- Note: With your permission, we may share your proposal with other researchers as an example if asked, or describe the details of your proposal to other HathiTrust users. We will not post your proposal online. In all cases, we reserve the right to describe how datasets have been used by recipients, based on publicly-available information, including linking to research outputs from HathiTrust dataset usage.
- Sign and return the researcher agreement that applies to the data you are requesting.
- When your request is approved, we will ask you to send a static IP address. Once your access is cleared, then you will be able to rsync the data you have requested only from that IP address.
Google Distribution Agreements
The following institutions have signed a Distribution Agreement with Google for controlled use of texts.
-
-
- Arizona State University
- Boston University
- Carnegie Mellon University
- Clemson University
- Columbia University
- Cornell University
- Dartmouth College
- Georgetown University
- Georgia Institute of Technology
- Harvard University
- Indiana University
- Lehigh University
- McGill University
- Michigan State University
- Northeastern University
- Pennsylvania State University
- Princeton University
- Purdue University
- Queen’s University at Kingston
- San José State University
- Stanford University
- State University of New York at Stony Brook
- Texas A&M University
- University of California
- University of Chester
- University of Chicago
- University of Colorado
- University of Illinois
- University of Iowa
- University of Massachusetts, Lowell
- University of Miami
- University of Michigan
- University of Oxford
- University of Toronto
- University of Vermont
- University of Virginia
- University of Waikato
- Wellesley College
- Westfälische Wilhelms-Universität Münster (University of Münster)
- Yale University
-
Deletion notifications
Occasionally we determine that items have erroneously been identified as public domain. When this happens we close the item and update the rights status of volumes in the public domain datasets. Dataset recipients are then responsible for deleting those items from their dataset. Dataset recipients are added to an email list, from which they receive emails when there are files to delete. It is HathiTrust’s expectation that you will remove them from your dataset, and this requirement is stipulated in the agreements signed by each recipient.
Retrieving Datasets via rsync
Static IP
Permission to rsync the data is tied to the IP address you supply during the final step of the dataset approval process. Because the IP address associated with your computer is likely to change from day-to-day, we recommend that you send a static non-NAT IP address. You may need to work with someone in IT at your institution to establish a static IP address.
File paths
If you want to download a subset of volumes from one of the datasets, you will need to supply the files paths for the selected volumes in order to rsync just those volumes. Instructions and Python, Ruby, and Perl code to generate the file paths for volumes based on their HathiTrust ID are available in this instruction guide. First create a text file with the HathiTrust IDs for the volumes you would like to rsync, for example by downloading the metadata for a HathiTrust collection and editing the file so that it is a single column of HathiTrust IDs. Make sure you have Python, Ruby or Perl installed. From the command line, run the command in your language of choice as written in the instruction guide.
rsync
Datasets are retrieved using rsync. Rsync is a utility for transferring files. It is standard on Mac and Linux computers and can be run from the command line (e.g., the Terminal application on a Mac). Windows users can install cwRsync – Rsync for Windows or Cygwin in order to use rsync. If using Cygwin, you can choose which utilities to include during installation. Make sure you pick rsync. Follow these instructions to rsync the dataset. Most of the options in the gist are necessary, but a few are optional. For example, you could use the option –verbose only on updates to get a list of what changed. Please contact HathiTrust if you want more information about the options.
It’s possible that rsync will report errors, and quite likely that most will be harmless. We do not have a catalog of likely errors, so if you receive some, please forward them to us.
Depending on the size of your dataset, the initial rsync may take up to a day or more. One benefit of rsync is that if the process is terminated, you will not waste time transferring the same information again when you restart the sync. It will pick up where it left off, after comparing the source and target files. We update the datasets regularly as new materials are updated to HathiTrust. If you have a download in progress while we make an update to a dataset, your rsync will be terminated. To recover, simply restart rsync. It will spend time comparing the source and destination trees, but it will not waste time downloading anything already present on the destination.
Dataset Format
Once you sync the dataset, you will find a directory for each namespace at the top level, a file containing a list of the volume IDs in the dataset (id), and one or more files containing the bibliographic data for the items in the dataset (meta*.json.gz).For each item there are two files, a metadata file (<id>.mets.xml) and a zip file with the page text files (<id>.zip).
Other Policies and Procedures
Dispersed research teams
If the primary researcher on the request is from an institution with a signed Google Distribution Agreement and/or inside the U.S. and another team member is not:
-
-
- The data with the higher approval level may be rsynced only to the primary researcher
- Others on the project team can be allowed access to the data by the primary researcher, but only without moving the data off the servers of primary researcher. There may be no redistribution of the data, and no copying or moving of the data to the servers of the other research team members located in other jurisdictions.
- If the research team cannot agree to this, we will authorize the entire team for the lower access level only (e.g., non-Google Digitized, or public domain worldwide items).
-
Sharing results
Dataset recipients are welcomed to share the results of any research outcomes from their use of the dataset.The citation should contain a few key components:
-
-
- An author name. If you are using a full dataset
- Recognition of that the data was received from HathiTrust.
- A title describing your dataset.
- If you are working with a subset of volumes, link to the HathiTrust collection, HTRC workset, or volume ID list that corresponds to your dataset.
- An access date.
-
HathiTrust. TITLE DESCRIBING YOUR DATASET. Distributed by HathiTrust (Requesting and Using Research Datasets). LINK TO COLLECTION/WORKSET/VOLUME ID LIST. Accessed DATE.
- Example for dataset corresponding to HathiTrust collection:
HathiTrust. Adventure Novels: G.A. Henty. Distributed by HathiTrust (https://www.hathitrust.org/datasets). https://babel.hathitrust.org/cgi/mb?a=listis;c=464226859. Accessed December 1, 2019.
- Preferred citation format
-
- We have prepared a Python library with code for working with the pairtree structure and removing headers and footers from the files. The code is available here: https://github.com/htrc/ht-text-prep. If you need more information about the files or file structure, let us know (support@hathitrust.org).
- The directory tree under each namespace is in pairtree format based on the HathiTrust volume IDs. Tools to help with pairtree usage can be found athttps://confluence.ucop.edu/display/Curation/PairTree. Data for any given volume is found at the end of a pairtree directory structure created using the HathiTrust IDs.
- Data format
-
- It’s possible that rsync will report errors, and quite likely that most will be harmless. We do not have a catalog of likely errors, so if you receive some, please forward them to us.
- rsync
- File paths
- HathiTrust expects that you will either continue with the deletions for the long term, or delete the entire dataset from your machine. If you want to stop receiving the deletion notifications, then you can delete the dataset and let HathiTrust know by emailing support@hathitrust.org.
Metadata Sharing Policy
Under HathiTrust Digital Library’s (HTDL) Metadata Sharing Policy, independent users, member institutions, and other third parties are free to harvest (for example, through our OAI feed or the HathiFiles), modify and/or otherwise make use of any metadata contained in HTDL unless restricted by contractual obligations residing with the parties that have contributed the metadata (“Depositing Institutions”) to HTDL. Furthermore, HTDL provides no warranties on the data made available through any sharing mechanisms. Use of the data is undertaken at the user’s own risk. Any contributions made by HTDL to the metadata in the repository have been placed into the public domain by HTDL via a CC0 Public Domain Dedication.
Questions About Datasets?
Contact our member-led user support team!